
While real news has been busy with important events, recent geek headlines have been dominated by a spectacularly public feud between search megalith Google and Microsoft’s relatively young competitor, Bing.
Of course, competitors are naturally suspicious of one another. Corporate sabotage is as old as corporations themselves. But, according to Google Fellow Amit Singhal, Google grew particularly suspicious of Bing in the summer of 2010.
Early in the summer, someone could Google for “torsorophy” and Google would suggest that the user search for “tarsorrhaphy” instead — the name of a rare eye surgery. Meanwhile, Bing remained incapable of making this correction, and would deliver its users results that matched the literal string “torsorophy.”
That changed later in the summer. Suddenly, a Bing search for “torsorophy” (the misspelled term) began returning Google’s first result for “tarsorrhaphy” (the correctly spelled term) without offering any spelling correction to the user.
From Singhal’s blog:


“Torsorophy” is a rare search term. Intuitively, it seems improbable that two independently-designed search algorithms could come up with the same answer for such an uncommon query. For Singhal, Bing’s change represented a chance that Bing was directly copying off of Google’s search results.
So Singhal decided to set up a sting operation (or, in his words, “an experiment”):
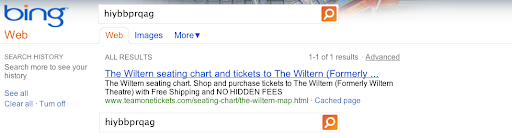
We created about 100 “synthetic queries”—queries that you would never expect a user to type, such as “hiybbprqag.” As a one-time experiment, for each synthetic query we inserted as Google’s top result a unique (real) webpage which had nothing to do with the query.
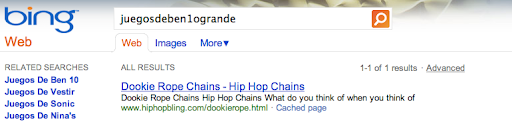
In this case, [hiybbprqag] returned a seating chart for the Wiltern Theater in Los Angeles. The term “juegosdeben1ogrande” returned a page for hip hop fashion accessories.
{kind=link}
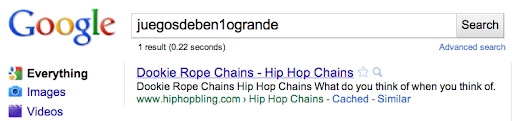{kind=link}
[T]here was absolutely no reason for any search engine to return that webpage for that synthetic query. You can think of the synthetic queries with inserted results as the search engine equivalent of marked bills in a bank. […] We asked these engineers to enter the synthetic queries into the search box on the Google home page, and click on the results, i.e., the results we inserted.
Within a couple weeks, Bing started matching Google’s planted results. Singhal concluded that Bing must be using some means to “send data to Bing on what people search for on Google and the Google search results they click.”
{kind=link}
{kind=link}
The VP of Bing, Harry Shum, quickly fired back a public response:
We use over 1,000 different signals and features in our ranking algorithm. A small piece of that is clickstream data we get from some of our customers, who opt-in to sharing anonymous data as they navigate the web in order to help us improve the experience for all users.
(For the record, my personal research indicates that Bing marks their “opt-in” feature by default. It would be more accurate for Shum to say that Bing learns from customers who fail to opt-out of Bing’s clickstream.)
In a recent “Future of Search” event, Shum clarified extemporaneously:
It’s not like we actually copy anything. It’s really about, we learn from the customers — who actually willingly opt-in to share their data with us. Just like Google does. Just like other search engines do. It’s where we actually learn from the customers, from what kind of queries they type — we have query logs — what kind of clicks they do. And let’s not forget that the reason search worked, the reason web worked, is really about collective intelligence.
The confusing aspect of this row is that Google nor Bing seem to be lying. Instead, Google is calling Bing’s practice cheating while Bing feels that seeing what its customers find on other search engines — and using that data to tailor its own results — is fair game.

So Google and Bing’s feud is a lot more complex than Bing’s copying search results from Google. First, Bing gets their information from users who “opt-in” to share the searches they make in Bing’s toolbar — a toolbar that can search numerous search engine, Google included.
Second, Bing didn’t recreate, hack or steal Google’s algorithm. That would be intellectual property theft. Instead, Bing treated Google’s algorithm the same way any normal user would: (that is, like a black box: some input goes in, some input comes out). Bing called upon its users to find this mysterious algorithm’s output, and then used the harvested Google output to inform Bing’s own decision.
But Google’s patented algorithm (and the many algorithms that support it, like Google’s spelling correction algorithm) is a really big deal in the search engine world. The PageRank algorithm (right) works by tracking enormous networks of links, then using these data to construct a new network: one of complex probabilities that try to answer the question, “Which page are you probably trying to find?”
The tempting analogy here — and the analogy Google would like us to use — is one where a student peeks over at his classmate’s paper during an exam when he doesn’t know an answer. When Bing is sure it has an answer, it may be less likely to look over at Google’s blue book. But when someone searches Bing for something uncommon, like “torsorophy” or “juegosdeben1ogrande,” Bing’s algorithm is capable of looking at Google’s answers and allowing those .
The question is not whether or not Bing copied results from Google. Both sides assert that, in one way or another, Google’s results worked their way into Bing’s. The question is whether or not this flavor of copying is fair game, or if it’s unfairly piggybacking on Google’s hard work.
The cheating analogy expresses a clear opinion on who’s wrong and who’s right in this mess. It frames Bing as the dumb jock cheating off the smart kid’s test (and anyone who cares about this debate enough to read this far is likely to associate with the smart kid). But it doesn’t capture the full subtlety of what exactly has been going on between Google’s search results and Bing’s.
Consider Dogpile. Dogpile is a “meta-search.” It compiles results of several search engines (including Google and Bing), seeing where they agree and aggregating result unique to each engine. Essentially, it searches searches.
And Dogpile doesn’t try to hide their aggregate searching: if you Google for Dogpile, you’ll see:

So why has Bing gotten into trouble while Dogpile — the original meta-search engine — has avoided the negative press? Both Dogpile and Bing use Google’s output to inform their final output. And, at the end of the day, Dogpile “cheats” off of Google much more directly than does Bing (Dogpile queries Google directly instead of using its users as an intermediate).
In 2007, Dogpile published a study touting the benefits of searching searches:

Of course, unlike Dogpile, Bing didn’t credit Google as a source in compiling its search results. But let’s pretend that Bing decides to do what Dogpile does. Let’s pretend that, tomorrow, Bing will start crediting the search engines from which it collects data. Let’s say that Bing will continue to combine meta-search data with the numerous other factors it considers, but when it spits out the results, it includes a note about how it effectively meta-searches certain external engines. Would Google’s beef disappear? Would Bing, like Dogpile, be safe from criticism?
Consider this analogy: Bing, like the rest of us, is a Google user. And like the rest of us, Bing doesn’t actually care how Google arrived at its answers. It’s just curious what answers Google can give it. It uses Google’s output as one of many inputs into its own algorithm. Bing’s black box, like Google’s, uses some public tools (unprotected sites, databases and link depositories) and some private tools (the sum total of its many algorithms) to create search results for its user. The difference is that Bing uses one public tool in creating search results that Google doesn’t use: the results of other search engines.
And Google Search is a public tool, supported by sponsors in the form of advertisements. Anyone can Google a query and receive their results, free of charge. Unlike an exam, a Google search is available for everyone to cheat off of — including other search engines. So, why should one particular public tool be off-limits to the designers of search engines? If search engines can freely search public sites, indicies, and databases, why can’t search engines freely search searches?
Here’s a more appropriate schoolroom analogy: Google and Bing are two students on opposite sides of a classroom, each writing the answers to the same test on opposing chalkboards. While Google is busy tabulating its results in isolation, Bing doesn’t consider its answer complete until it’s turned around to see what Google got.
Some internet users (including this one) may sense sleaziness in Bing’s failure to credit Google for contributing to its end product. But certainly it’s Bing’s lack of citation, not their so-called cheating, for which the designers of the search tool are to blame.
After all, Bing’s search algorithm isn’t doing anything different from what your normal Google user does everyday: querying an opaque system and using that system’s output to inform decision-making. Should I be crediting Google every time Google’s algorithm is indirectly responsible for my pulling a profit? If so, I owe them a solid percentage of my wages — I found SONIC lab through a Google search.
Further reading: