
Weak ties may just be weak
In this month’s edition of WIRED magazine (May 2011), writer Clive Thompson made a startling assertion. Mark Granovetter’s “The Strength of Weak Ties” has been at the foundation of many different network theories since its publication in 1973. But Thompson says that this may not be true. Based on in-press research done by Sinan Aral and Marshall Van Alstyne, they find that even though a person who is dissimilar to you may have interesting things to say, the fact that you don’t interact with them very often (the weak tie) greatly reduces the probability of them actually telling you something interesting and instead the people you interact with very often (the strong ties) have a much higher likelihood of tell you something new. This article is set to be published this summer.
Wikipedia Breaking News Picked up by Forbes
The visualization we featured about the Tohoku earthquake and tsunami was featured by a Georgia Tech professor Amy Bruckman at the MIT Media Lab’s “Sandbox Summit” and subsequently picked up by David Ewalt at Forbes magazine in a blog post “Playing Well With Others“.
SSRN extracts and links citations
The Social Science Research Network has just announced the beta release of their citation extraction initiative. This new large-scale citation data will be particularly interesting to those who study citation behavior, especially in the SSRN’s main fields of law and business. The SSRN’s focus on working papers means that much of the work available is at the cutting edge of its field. This allows for interesting comparative approaches studying the citation networks of peer-reviewed published works and working papers.
To view citation information visit SSRN, find a publication of interest and click the ‘references’ or ‘footnotes’ tab. While not all of the papers have had their citation information extracted many have and more are being processed as the project progresses.
AAP Updates Guidelines on Kids and Social Media
When you tell parents that you study kids and social media, they invariably complain about Facebook (or it’s pre-teen brethren, Club Penguin and Togetherville), and ask if all this social networking is good or bad for kids. As with many social science questions, the answer, of course, is “it depends.”
A new report in the April issue of Pediatrics, the journal of the American Academy of Pediatrics, weighs in on the issue and encourages pediatricians to talk about social media and online social networking with parents. Although the report doesn’t get deep into network science, it does allude to some of the common findings from our field. For instance, the authors cite studies suggesting that kids can benefit by expanding their networks online to include contacts that are more numerous and diverse than they may otherwise encounter in their offline networks, affording them access to information and resources they might not otherwise have. Likewise, kids may be able to find communities of practice online where they can build social skills and participate in collective action around a cause that matters to them.
The authors also warn of the potential downsides of online networks, including increased risk of cyberbullying, sexting, and something they call “Facebook depression,” which they imply (without the benefit of many peer-reviewed references) can arise when there is a mismatch between the perception of social support and acceptance from online networks, and the actual support and acceptance received from those networks.
The report concludes with a series of generalized warnings about online privacy, and recommends that pediatricians discuss online social networking with the parents of their patients, in light of the, “challenging social and health issues that online youth experience.”
Personally, I was happy to see that the AAP is talking about social media, even if the report was a bit alarmist for my tastes. I think the privacy risks were somewhat overstated, and I would have liked to see more emphasis on placed on the role that online media play in strengthening existing social ties, an important benefit of social media that was not noted in the report.
What do you think? Does the report do a good job informing parents and doctors about the benefits and risks of social networking? Has your pediatrician discussed social networking sites with you or your children?
Read the full report, here: http://pediatrics.aappublications.org/cgi/reprint/peds.2011-0054v1
Or the press release from the AAP, here: http://aap.org/advocacy/releases/socialmedia2011.htm
Wikipedia articles affected by Tohoku earthquake
Brian Keegan’s dissertation will use Wikipedia’s coverage of breaking news articles to examine the high-tempo and high-reliability coordination practices of emergent, self-assembling teams. Wikipedia’s response to and coverage of the tragic events over the past week in Japan continues to provide a fascinating corpus for analysis. Some factoids:
- The English article about the earthquake with links to the relevant sites for the US Geological Survey and Integrated Tsunami Watch Service was started at 6:18 GMT, just over 32 minutes after the earthquake began. The bureaucratic editorial process of nominating it to appear on the front page of Wikipedia was begun at 6:29. The article appeared on the front page by 7:58 after being vetted by 12 editors and at least one administrator. As a point of comparison, The New York Times (the first to report according to Memeorandum) did not file a story until 7:35.
- Between the start of the article and noon CDT on March 15 (~100 hours after the earthquake), 761 editors made 2,901 contributions. The average time between edits over this entire window was 2 minutes, 4 seconds. The median was 1:08.
- At the time, 49 other articles had been categorized by Wikipedians as being affected by or related to the earthquake and tsunami. 1683 unique editors made 6,931 contributions to these articles, including the one above. In that 100 hour time window, the average interval between edits made to articles in this category was 56 seconds. The median was 37 seconds.
A (very crude) temporal visualization of how the activity among editors to these articles can be seen in the video below. The text is admittedly hard to read, try full-screening the video. The red nodes are the articles, the blue nodes are editors, and the links indicate which editors edited which articles. The “halos” of small blue nodes around the articles are the editors who contributed only to that article and none of the other articles. The clump of larger blue nodes in the center are editors who contributed to many of the other articles. Be sure to pay attention to when they make the switch to only editing one article to editing others. Note the switch in “attention” from the article about the earthquake & tsunami to the nuclear reactor as well as the lag before the articles about the affected communities (located at approximately 1 o’clock) are updated. The article at approximately 3 o’clock is the “Fukushima I nuclear accidents” article which is created more than 48 hours after the earthquake itself.
100 Hours of Wikipedia activity for Sendai earthquake from Brian Keegan on Vimeo.
Social network analysis fights crime on Chicago’s west side
Chicago Police Target Most Violent Gang in Harrison District
Social Network Analysis Aides Efforts to Dismantle Gang Network
Chicago Police Department press release , 2011-02-13
Superintentent Weis emphasized the utility of Social Network Analysis for identifying perpetrators of violence so that gang factions may be dismantled. The Analysis also reveals the relationships between victims and offenders in shooting and homicide incidents, highlighting that both parties often are known to each other through personal disputes, and that violence is not random but intentional. … Social Network Analysis effectively enables law enforcement to identify at-risk individuals and make appropriate outreach.
Weis: Gang crackdown led to crime decrease
Police met with gang leaders, focused on social network
February 13, 2011, Andy Grimm, Chicago Tribune
Weis said the department has built a social network database that combines gang, vice and patrol officers’ insights at the street level and arrest data to show links between gang members, helping the department to better target enforcement.
University of Massachusetts sociologist Andrew V. Papachristos, who has studied Chicago gangs for his graduate research at the University of Chicago, said social network analysis has been successful in crime reduction efforts in smaller cities such as Boston and Cincinnati.
“We use the words ‘crime epidemic.’ … Well, if it is an epidemic, it should follow certain rules as to how it spreads,” Papachristos said.
Chicago police fight crime in new ways
Paul Meincke, WLS-TV ABC7 News, Monday, February 14, 201
Police are using what they call social network analysis. It starts with what street cops know, then that gets analyzed by computer which compares crime patterns and arrests going back in time.
“One thing we know about crime is it’s a lot like sex: who you mess around with is going to get you into trouble,” said Harvard Professor Andrew Papachristos.
Partner Knowledge Awareness: A Better Way to Learn?
 Just recently published this year in the Journal of Experimental Education, an article titled Partner Knowledge Awareness in Knowledge Communication: Learning by Adapting to the Partner sheds interesting new insight on educational methods.
Just recently published this year in the Journal of Experimental Education, an article titled Partner Knowledge Awareness in Knowledge Communication: Learning by Adapting to the Partner sheds interesting new insight on educational methods.
First, Partner Knowledge Awareness (PKA) is defined to be a “phenomenon in which a person is aware of aspects of another group member’s knowledge. Awareness refers to an individual’s mental state, partner prefers to the target of the mental representation, and knowledge refers to the relevant characteristic of the target.”
This article primarily focuses on the effect of PKA on learning outcome and processes. For example, “during explanation, for instance, one collaborator can use PKA to adapt explanations toward the partner’s knowledge.”
Essentially, PKA induces a cognitive process when dealing with information, which is known as knowledge transforming. The authors explain, “adapting explanations to a partner is thought to foster one’s own understanding and learning to the extent that the explainer will clarify and reorganize the material in new ways to make it more understandable to others.” Although not the most complicated concept, it brings up the question how much of a beneficial educational impact this cognitive process can have.
Performed in Germany, the experiment involved about 49 native students. Each were given about 25 minutes to study extensive hypertexts about blood constituents and the immune system. Afterward, the subjects were randomly assigned into groups of three. One member, the explainer, of each group was given the responsibility to explain the material to the other two, the recipients.
The explainer was given a visualization tool before he or she had to begin:

You may be wondering, what exactly is this image? It is PKA! On paper!
After learning the material, every participant filled out a sheet of paper, like the one above, marking what he or she didn’t know. The explainer is now aware of the parameters of both of the recipients’ knowledge on the material; consequently, the visualization tool fosters and creates PKA for the explainer to adapt, improve, and specialize their explanations.
Afterwards, all the participants were tested on the material by taking a 36 multiple-choice exam. The results for the recipients, the subjects who had the material explained to them, were not surprising: they scored higher than those who had taken the exam without receiving explanations. However, the surprising result was that the explainers, who were given the PKA visualization tool, significantly scored much higher than the control group, explainers who did not receive the PKA. The explainers with PKA not only had the greatest improvement in scores but the highest scores overall. The authors explain, “Not only can other group members potentially benefit from these adaptations, but one of the major arguments here is that explainers using PKA information themselves are supported in their learning. The one adapting is the one benefiting.”
What this article suggests is neither groundbreaking nor very modern. The idea that “teaching is the best way to learn” has been around for ages. However, what this study does suggest is a simple method, which can be as simple as a piece of paper, that fosters huge learning benefits for everyone. In fact, the idea is so simple that it is rather striking that educators don’t implement this sort of knowledge communication more often.
So as I try to pay attention to the complicated jargon my professor is simultaneously mumbling and drawing on a dirty chalkboard, I can’t help myself asking the very questions this article brings up. Wouldn’t my professor explain the material more effectively if they were aware of what I do and do not know? Wouldn’t my understanding be taken to new heights if I were forced to try explaining the material in my own words rather than sitting in class writing and memorizing everything someone else says verbatim? Wouldn’t knowledge communication be more beneficial than knowledge memorization?
I shrug my shoulders, excommunicate myself in the library, and begin to cram for the next midterm, unaware of a better way to learn and understand the countless numbers, terms, and words that seem to dominate my life.
Social Network Analysis of Bullying in High Schools

The New York Times featured a fascinating recent report on who gets bullied, who does the bullying, and why. You need to have a fairly sharp eye to notice from the NYT blog post that the paper is really about social network analysis, however! The blog post, titled “Web of Popularity, Achieved by Bullying” doesn’t mention social networks until the last few paragraphs and keeps away from any technical terms. (It does have some very interesting comments from NYT readers, however.) To glean a little more about the social network analysis content, you can go directly to the full text of the scholarly article, “Status Struggles: Network Centrality and Gender Segregation in Same- and Cross-Gender Aggression” by Robert Faris and Diane Felmlee, published in the American Sociological Review.
Faris and Felmlee’s research challenges the common conception that bullying can be attributed to negative personality traits of the individual and generally comes from individuals who are maladjusted to their environment. The paper points out that the bulk of research on aggression comes from psychology, which may explain some of the usual focus on individual agency rather than network effects. Instead of looking for traits commonly possessed by bullies, Faris and Felmlee argue that “[a]s peer status increases, so does the capacity for aggression, and competition to gain or maintain status motivates the use of aggression” (pg. 49). One of the primary arguments of the article is that high school students who are “more popular,” or who have higher betweenness centrality, have more status and thereby more power. They are able to employ this power to aggressive ends in order to further their status or fend off challenges to their status by other students.
One of the most interesting findings in the study is that while there is a positive relationship between network centrality and aggression, this only holds true up until the very top of the social hierarchy. When students become so central that they are present in about one of every four of the shortest paths (geodesics) between any two students, their aggression drops off noticeably (pg. 57). The authors posit that individuals at the top no longer need to be aggressive to climb to the top of the hierarchy and that doing so might be interpreted as a sign of status insecurity or weakness.
Of course, as the full title above suggests, the researchers also looked into the effects of gender segregation on student aggression. In largely gender-segregated environments, some students serve as a special type of network bridge by virtue of having multiple friends of the opposite gender. Essentially, these students can provide same gender friends with access to weak ties that are particularly valuable to high school students: students of the opposite gender. The students who serve as gender bridges are likely to be much more aggressive in their cross-gender relationships than comparable peers with similar centrality.
The full text of the article goes into much more detail about methodology and data collection, and also has a few network graphs that make it a little easier to understand the cross-gender relationships. Even if your network analysis chops aren’t quite up to slogging through the detailed tables, the beginning of the article does a great job of succinctly summarizing the findings and offers a lot of interesting tidbits about high school students via references to other research. For example, did you know that approximately one third of high school students engage in aggression, and an estimated 160,000 students skip school every weekday to avoid being bullied?
What do you think? Do students at the very top of the social hierarchy no longer need to use aggression, or is there another explanation? Could their immediate subordinates on the hierarchy chain, who have the highest levels of aggression recorded, pick up the slack for the very top status students in hope of currying favor or increasing their own status or the status of their microculture?
One of the things that might bear a little more examination in this paper is the definition of “aggression”. The fact that students who date are 23% more likely to be “aggressive” and the gender bridge exhibiting increased cross-gender “aggression” suggest that some of the aggressive behavior is not necessarily carried out with hostile intent. The framework of the paper gives a negative moral valence to aggression, while some of the aggression measured in the survey might not be so negative, or at least, might not be viewed as a negative as the students progress from 8th to 12th grade over the course of the longitudinal study. In my personal opinion, I suspect that some of the cross-gender aggression is not so much negative behavior as a variable that has confounded more than just academic papers: flirting.
Google, Bing & searching searches
While real news has been busy with important events, recent geek headlines have been dominated by a spectacularly public feud between search megalith Google and Microsoft’s relatively young competitor, Bing.
Of course, competitors are naturally suspicious of one another. Corporate sabotage is as old as corporations themselves. But, according to Google Fellow Amit Singhal, Google grew particularly suspicious of Bing in the summer of 2010.
Early in the summer, someone could Google for “torsorophy” and Google would suggest that the user search for “tarsorrhaphy” instead — the name of a rare eye surgery. Meanwhile, Bing remained incapable of making this correction, and would deliver its users results that matched the literal string “torsorophy.”
That changed later in the summer. Suddenly, a Bing search for “torsorophy” (the misspelled term) began returning Google’s first result for “tarsorrhaphy” (the correctly spelled term) without offering any spelling correction to the user.
From Singhal’s blog:


“Torsorophy” is a rare search term. Intuitively, it seems improbable that two independently-designed search algorithms could come up with the same answer for such an uncommon query. For Singhal, Bing’s change represented a chance that Bing was directly copying off of Google’s search results.
So Singhal decided to set up a sting operation (or, in his words, “an experiment”):
We created about 100 “synthetic queries”—queries that you would never expect a user to type, such as “hiybbprqag.” As a one-time experiment, for each synthetic query we inserted as Google’s top result a unique (real) webpage which had nothing to do with the query.
In this case, [hiybbprqag] returned a seating chart for the Wiltern Theater in Los Angeles. The term “juegosdeben1ogrande” returned a page for hip hop fashion accessories.
{kind=link}
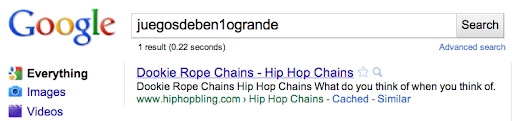{kind=link}
[T]here was absolutely no reason for any search engine to return that webpage for that synthetic query. You can think of the synthetic queries with inserted results as the search engine equivalent of marked bills in a bank. […] We asked these engineers to enter the synthetic queries into the search box on the Google home page, and click on the results, i.e., the results we inserted.
Within a couple weeks, Bing started matching Google’s planted results. Singhal concluded that Bing must be using some means to “send data to Bing on what people search for on Google and the Google search results they click.”
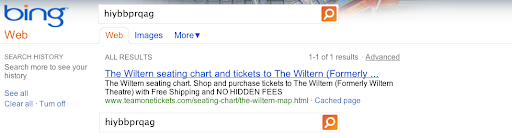{kind=link}
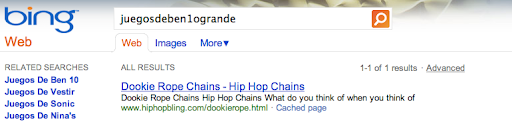{kind=link}
The VP of Bing, Harry Shum, quickly fired back a public response:
We use over 1,000 different signals and features in our ranking algorithm. A small piece of that is clickstream data we get from some of our customers, who opt-in to sharing anonymous data as they navigate the web in order to help us improve the experience for all users.
(For the record, my personal research indicates that Bing marks their “opt-in” feature by default. It would be more accurate for Shum to say that Bing learns from customers who fail to opt-out of Bing’s clickstream.)
In a recent “Future of Search” event, Shum clarified extemporaneously:
It’s not like we actually copy anything. It’s really about, we learn from the customers — who actually willingly opt-in to share their data with us. Just like Google does. Just like other search engines do. It’s where we actually learn from the customers, from what kind of queries they type — we have query logs — what kind of clicks they do. And let’s not forget that the reason search worked, the reason web worked, is really about collective intelligence.
The confusing aspect of this row is that Google nor Bing seem to be lying. Instead, Google is calling Bing’s practice cheating while Bing feels that seeing what its customers find on other search engines — and using that data to tailor its own results — is fair game.

So Google and Bing’s feud is a lot more complex than Bing’s copying search results from Google. First, Bing gets their information from users who “opt-in” to share the searches they make in Bing’s toolbar — a toolbar that can search numerous search engine, Google included.
Second, Bing didn’t recreate, hack or steal Google’s algorithm. That would be intellectual property theft. Instead, Bing treated Google’s algorithm the same way any normal user would: (that is, like a black box: some input goes in, some input comes out). Bing called upon its users to find this mysterious algorithm’s output, and then used the harvested Google output to inform Bing’s own decision.
But Google’s patented algorithm (and the many algorithms that support it, like Google’s spelling correction algorithm) is a really big deal in the search engine world. The PageRank algorithm (right) works by tracking enormous networks of links, then using these data to construct a new network: one of complex probabilities that try to answer the question, “Which page are you probably trying to find?”
The tempting analogy here — and the analogy Google would like us to use — is one where a student peeks over at his classmate’s paper during an exam when he doesn’t know an answer. When Bing is sure it has an answer, it may be less likely to look over at Google’s blue book. But when someone searches Bing for something uncommon, like “torsorophy” or “juegosdeben1ogrande,” Bing’s algorithm is capable of looking at Google’s answers and allowing those .
The question is not whether or not Bing copied results from Google. Both sides assert that, in one way or another, Google’s results worked their way into Bing’s. The question is whether or not this flavor of copying is fair game, or if it’s unfairly piggybacking on Google’s hard work.
The cheating analogy expresses a clear opinion on who’s wrong and who’s right in this mess. It frames Bing as the dumb jock cheating off the smart kid’s test (and anyone who cares about this debate enough to read this far is likely to associate with the smart kid). But it doesn’t capture the full subtlety of what exactly has been going on between Google’s search results and Bing’s.
Consider Dogpile. Dogpile is a “meta-search.” It compiles results of several search engines (including Google and Bing), seeing where they agree and aggregating result unique to each engine. Essentially, it searches searches.
And Dogpile doesn’t try to hide their aggregate searching: if you Google for Dogpile, you’ll see:

So why has Bing gotten into trouble while Dogpile — the original meta-search engine — has avoided the negative press? Both Dogpile and Bing use Google’s output to inform their final output. And, at the end of the day, Dogpile “cheats” off of Google much more directly than does Bing (Dogpile queries Google directly instead of using its users as an intermediate).
In 2007, Dogpile published a study touting the benefits of searching searches:

Of course, unlike Dogpile, Bing didn’t credit Google as a source in compiling its search results. But let’s pretend that Bing decides to do what Dogpile does. Let’s pretend that, tomorrow, Bing will start crediting the search engines from which it collects data. Let’s say that Bing will continue to combine meta-search data with the numerous other factors it considers, but when it spits out the results, it includes a note about how it effectively meta-searches certain external engines. Would Google’s beef disappear? Would Bing, like Dogpile, be safe from criticism?
Consider this analogy: Bing, like the rest of us, is a Google user. And like the rest of us, Bing doesn’t actually care how Google arrived at its answers. It’s just curious what answers Google can give it. It uses Google’s output as one of many inputs into its own algorithm. Bing’s black box, like Google’s, uses some public tools (unprotected sites, databases and link depositories) and some private tools (the sum total of its many algorithms) to create search results for its user. The difference is that Bing uses one public tool in creating search results that Google doesn’t use: the results of other search engines.
And Google Search is a public tool, supported by sponsors in the form of advertisements. Anyone can Google a query and receive their results, free of charge. Unlike an exam, a Google search is available for everyone to cheat off of — including other search engines. So, why should one particular public tool be off-limits to the designers of search engines? If search engines can freely search public sites, indicies, and databases, why can’t search engines freely search searches?
Here’s a more appropriate schoolroom analogy: Google and Bing are two students on opposite sides of a classroom, each writing the answers to the same test on opposing chalkboards. While Google is busy tabulating its results in isolation, Bing doesn’t consider its answer complete until it’s turned around to see what Google got.
Some internet users (including this one) may sense sleaziness in Bing’s failure to credit Google for contributing to its end product. But certainly it’s Bing’s lack of citation, not their so-called cheating, for which the designers of the search tool are to blame.
After all, Bing’s search algorithm isn’t doing anything different from what your normal Google user does everyday: querying an opaque system and using that system’s output to inform decision-making. Should I be crediting Google every time Google’s algorithm is indirectly responsible for my pulling a profit? If so, I owe them a solid percentage of my wages — I found SONIC lab through a Google search.
Further reading: